Our system, CherryBot, can handle challenging dynamic fine manipulation tasks in the real world. CherryBot operates in three phases: (1) pretraining in simulation on the proxy task, (2) fine-tuning in the real world on the same proxy task, and (3) deploying in the real world on test tasks. We then evaluate the resulting learned policy in a variety of dynamic scenarios. The image on the right details a deeper look at our hardware setup. Our robot is an assembled 6-DOF robotic arm equipped with chopsticks to perform fine manipulation, paired with either a motion capture cage or an RGB-D camera for perception.
The Problem
Grasping small objects surrounded by unstable or non-rigid material plays a crucial role in applications such as surgery, harvesting, construction, disaster recovery, and assisted feeding. This task is especially difficult when fine manipulation is required in the presence of sensor noise and perception errors; this inevitably triggers dynamic motion, which is challenging to model precisely.
Similar challenges arise in everyday interactions: to remove shells from flowing egg whites, to grasp noodles from soup, and for surgeons to remove clots from deformable organs. Given the ubiquitous nature of these problems, developing robotic solutions to automate these has immense practical and economic value.

Picking up egg yolks

Picking up noodles
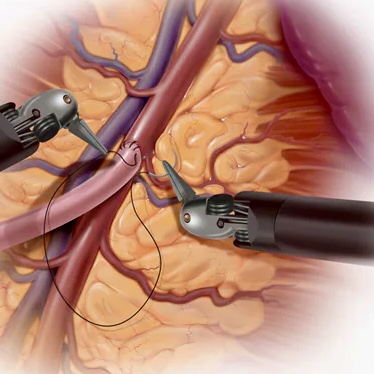
Removing clots from deformable organs
This work presents CherryBot, an RL system for fine manipulation that surpasses human reactivity for some dynamic grasping tasks. By carefully designing the training paradigm and algorithm, we study how to make a real-world robot learning system sample efficient and general while reducing the human effort required for supervision. Our system shows continual improvement through only 30 minutes of real-world interaction: through reactive retries, it achieves an almost 100% success rate on the demanding task of using chopsticks to grasp small objects swinging in the air. We demonstrate the reactiveness, robustness and generalizability of CherryBot to varying object shapes and dynamics in zero-shot settings (e.g., external disturbances like wind and human perturbations).





